

OK, not the whole org but all of its permissions, which will usually end up being almost the same.
At my last job I was helping a small company with k8s and app management and bringing everything up to SOC2 levels of security compliance. One task I spent some time on was getting the GCP IAM service accounts (using workload identity) for our apps under control of our gitops repo.
The system was configured with config connector(KCC), so making declarative changes to GCP resources boiled down to a relatively simple task of managing k8s resources. So I began searching for kcc documentation and noticed what looked like the perfect resource IAMPolicy.
One thing I frequently do with the kcc docs is to immediately scroll to the bottom to go over the resource samples as they often have enough data to figure out what I want to do at a high level, then I scroll back up to fill out knowledge on the resource's available fields.
What I failed to notice were all the giant red warnings at the top of the page.
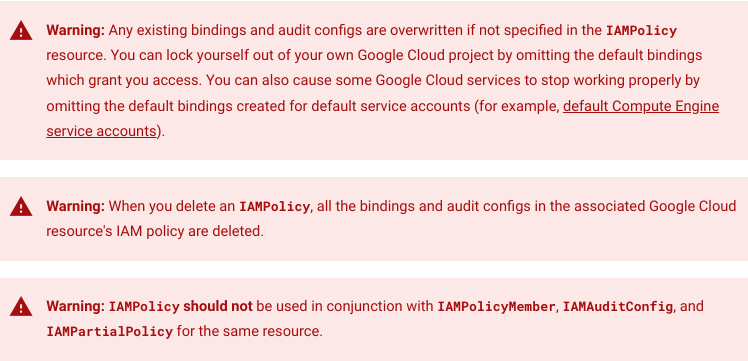
Wow, ok. So now I can see why creating an IAMPolicy targeting the GCP project was a bad idea (a large portion of the permissions were managed via clickops)...
I pushed the first permission change and then began working on the next. A few short seconds later the first slack message comes in about things not working. A lot of the app made use of GCP resources, like functions, cloud sql, and pubsub, so having the permissions disappear made it difficult to get much useful work done.
As providence would have it, my boss had used the config-connector CLI to do a bulk export of all the resources in the project and had all of the permissions saved as kcc resources. He applied them to the cluster and kcc recreated all of the project's permissions. We later stopped the kcc controller and removed the resources to go back to our previous posture.
Wat Learan?
Why tell this story? To smear myself? Well, it can happen to anybody, and thinking about how we failed and thinking about mitigations is an important part of improving the future of operating large compute systems for everyone.
So what can we learn? What could we change in processes or automation to keep similar things from happening in the future?
The gitops methodology provides too many benefits to just call for its removal, but with the power to make changes to your infra with simple git commits comes the power to unintentionally delete or irreparably alter your infra with a simple git commit.
On this front there are a few things we can do:
Staging project/cluster
The first obvious thing we can do is to have a staging project and cluster that we target changes at before it gets deployed on production. In this particular environment we did not have a project or cluster like this to test changes on.
Yes it would be painful to rebuild your staging environment, though the gitops methodology should make that pretty painless. But at least the only outage is internally facing and not impacting your customers.
GitOps Output Linting and Analysis
Doing linting or static analysis on the output of your gitops pipeline is still not something that's common. There are tools like conftest which can be used to write tests against your yaml config, though I don't think there are any industry-wide test packs that enforce best practices(though there are some in the policy engine space a la OPA gatekeeper).
This issue could have been mitigated by a test or policy that failed when an IAMPolicy targeting a project was committed or applied.
In fact, I asked my GPT4-based policy engine to create just such a policy:
apiVersion: gpt.drzzl.io/v1
kind: GPTPolicy
metadata:
name: no-iampolicy-targeting-projects.drzzl.io
spec:
description: "Deny any IAMPolicy config connector resources that targets a Project"This resulted in a jspolicy implementing my intent like so:
apiVersion: policy.jspolicy.com/v1beta1
kind: JsPolicy
metadata:
creationTimestamp: '2024-03-19T21:16:24Z'
generation: 1
name: no-iampolicy-targeting-projects.drzzl.io
ownerReferences:
- apiVersion: gpt.drzzl.io/v1
controller: true
kind: GPTPolicy
name: no-iampolicy-targeting-projects.drzzl.io
uid: f5794403-f498-4ca8-a9a2-a02e838dd9a6
resourceVersion: '109696173'
uid: 385ae777-2ad8-4ed1-bbda-23c77645071d
spec:
apiGroups:
- configconnector.cnrm.cloud.google.com
apiVersions:
- '*'
javascript: >-
if (request.object.spec.resourceRef.kind === 'Project') { deny('IAMPolicy
cannot target a Project'); } else { allow(); }
operations:
- CREATE
- UPDATE
resources:
- iampolicies
scope: Namespaced
type: ValidatingBummer, it got the api group wrong, it should be iam.cnrm.cloud.google.com, but you can see how simple it can be to create a policy to protect yourself from a failure like I caused.
This is one reason I'm a big fan of jspolicy, it's so much simpler to create and understand your policies compared to solutions like gatekeeper. As rego was intended to be kind of a multi-modal policy language, I view it as another notch on the do-everything-tool-failed pole.
Changelog
Showing the committer a diff of changes they're going to make to cluster resources is also something I haven't seen as a common tool implemented in gitops pipelines.
For some failure cases, and especially during local iteration, seeing the resource changes that are going to be made is incredibly helpful. This can be kind of slow, depending on the size of your repo, but a common workmode for me is to just do something like kustomize build apps/yoke/overlays/test/ in a terminal beneath my code.
At a previous gig I had created a tool that would generate the config for a particular path(e.g. kustomize build) in your local working set and then pulled master to a tmp directory to generate config from that same path there, and produced a diff of the two. I'll have to remember enough to recreate it OSS.
This is one reason that some gitops practitioners will use both a source and a generated repo. In the source repo are the helm charts, kustomizations, raw yaml, etc, and commits there get config generated by automation and committed to the generated repo where the cluster is actually pointed; this makes it incredibly easy to diff between deploys.
For this failure case however, I thought using this resource was reasonable, so showing me what I was changing would have only made me more confident.
Backups
This particular failure was solved with a backup, but it was not a backup part of a regular occurring automation, it was just a manual command with the output on my boss' workstation.
Having regular backups, saved to a different platform/project than the backups are protecting, could be critical in reversing gitops failures like this that might not be caught by an existing test or review.
Abandonment
An option of the kcc controller includes an attribute that tells it to Abandon a GCP resource when a kcc resource is removed from k8s, meaning it's left in place rather than deleted in kind.
This wouldn't have helped this failure, but in cases where you are managing resources which represent data not reproducable from the k8s resources themselves(like persistent volumes, kms keys, or cloudsql instances), it is best to set this attribute so that the data backed by the GCP resource can be saved against accidental kcc resource removal.
A test or policy to this effect could cover all known resources where it's best to set this, and mutate it in place or fail.
Future of GitOps
I love gitops, I think it's a nobrainer. I would include tooling like automated IaC pipelines that are triggered by a commit; tools like atlantis, spacelift, plumi and kcc itself(implemented mostly in terraform under the hood).
What I'd like to see in the future is the community coming together and building a pack of regression tests that can be applied to output yaml to catch known failures. I think there is also room here for ML to help in detecting target states that are undesireable and reject them with suggestions.
I think this all may present itself eventually as a "high-level language" for interacting with the platform that transpiles down to k8s resources. Dealing with low-level details in configuring and managing a k8s cluster, even if the controlplane is handled for you, is still a nontrivial task that involves knowledge in storage, compute, memory, networking, and firewalls.
This isn't a level that devs can work directly against in most cases and most automated tooling I mentioned requires the creation of bespoke abstraction layers to make it dev-friendly. In fact, in a lot of larger orgs one or more FTEs are invested on DX tooling overlaying their inhouse PaaS(k8s or otherwise) exactly because of this.