

I'm going to spend the next couple kilowords talking about how I view an LLM model's view of the world, and how we might map the LLM's conceptual-space to concept-first action spaces, like k8s-backed devops, to effect a higher-order persistent learning method driven by experimental success and failure.
Basically, I'm curious if we can get an bunch of LLM-based agents working together to create an kubernetes automation framework, via non-gradient trial and error, that you can drive with natural language requests, and I'm going to be running a series of experiements to that end.
Prior Artisans
One of my favorite AI papers is this interactive one that the authors published as a website, its goal: to explore the space of multi-agent LLM interaction models used to drive higher-order persistent learning with iteration around and through experimentation, and a clever code-based memory system, all towards the setting and reaching of long-term goals in a ruled system.
They say it best in the introduction of the paper:
We introduce Voyager, the first LLM-powered embodied lifelong learning agent in Minecraft that continuously explores the world, acquires diverse skills, and makes novel discoveries without human intervention. Voyager consists of three key components:
1) an automatic curriculum that maximizes exploration,
2) an ever-growing skill library of executable code for storing and retrieving complex behaviors, and
3) a new iterative prompting mechanism that incorporates environment feedback, execution errors, and self-verification for program improvement.
Voyager interacts with GPT-4 via blackbox queries, which bypasses the need for model parameter fine-tuning. The skills developed by Voyager are temporally extended, interpretable, and compositional, which compounds the agent's abilities rapidly and alleviates catastrophic forgetting.
Empirically, Voyager shows strong in-context lifelong learning capability and exhibits exceptional proficiency in playing Minecraft. It obtains 3.3x more unique items, travels 2.3x longer distances, and unlocks key tech tree milestones up to 15.3x faster than prior SOTA. Voyager is able to utilize the learned skill library in a new Minecraft world to solve novel tasks from scratch, while other techniques struggle to generalize.
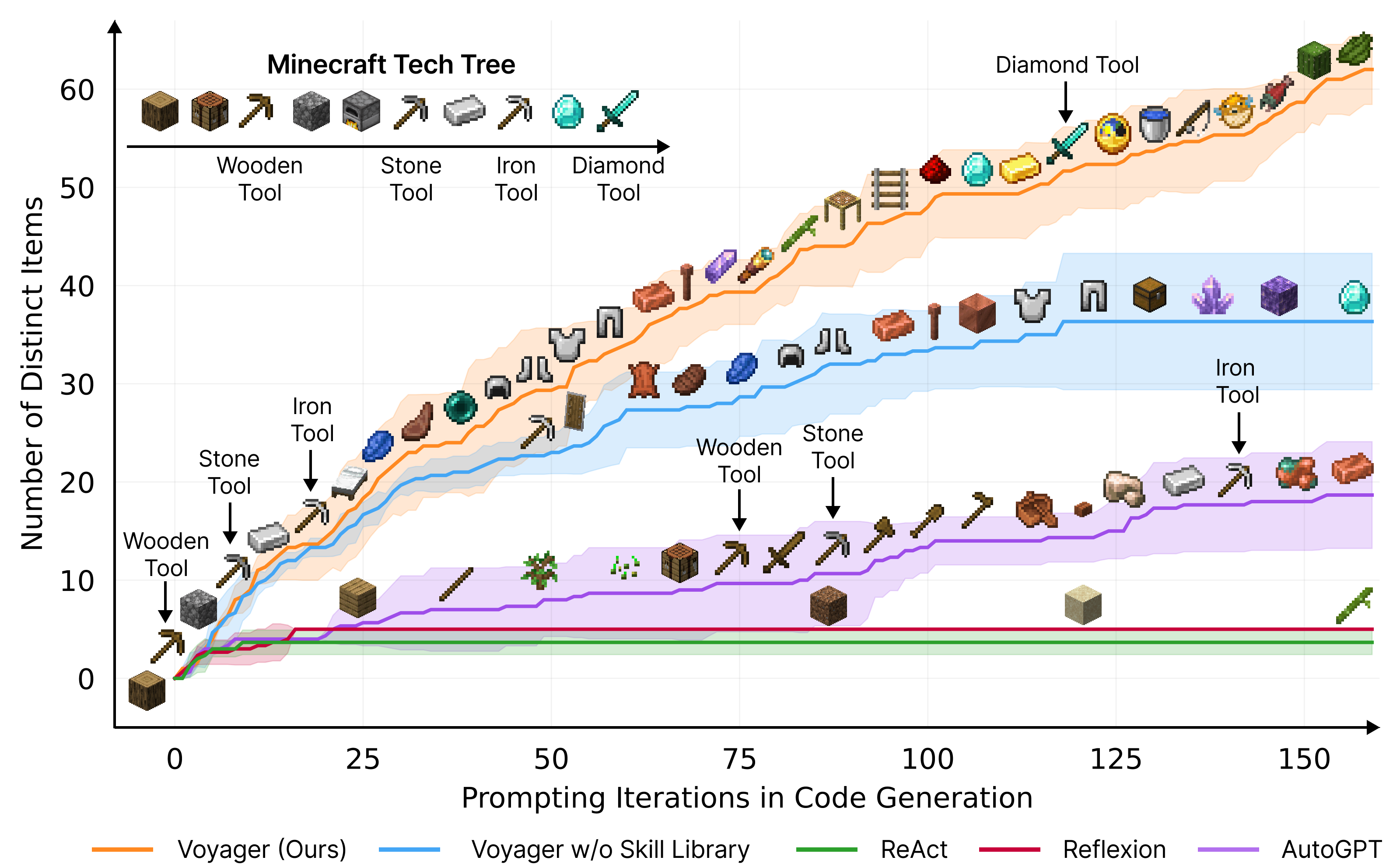
I'm not particularly skilled at the mathematical intuition equal to implementing the tech underlying modern AI implementations, like transformers; but when they're used to generate software, an area where I have significant experience, the LLMs and I now have a relatively complex, and strict, shared conceptual model in which to poke at boundaries.
Our interaction with the world is so much in our language, it seems peculiar to find such a golem that seems to be able to easily generalize multi-modal human communication, and particularly excels when driven with conceptual constraints set in freeform human language, with all its beautiful vagaries.
Many struggles here mirror those in communicating between humans: shared context and context-free vernacular in particular, but with the addition that interactions with a statistical model feel unanchored.
Higher Order Conceptual Modeling
I think one thing people don't explicitly talk much about with LLMs is their multi-order conceptual capabilities. While saying that they're "next word guessers" is a somewhat technically accurate–though often pejorative–way techies sometimes like to describe LLMs, I think it really undersells how many levels of conceptual context lies beneath each "guess".
Each token the model operates on is represented as vector in a space that often has many thousands of dimensions. These degrees of freedom allow every token to represent an incredibly complex conceptual representation where those concepts draw on the training and usage context. When ignoring things like homonyms, any instance a word–like "apple"–can mean the same thing in every case while also being used in one of an infinite set of possible contexts.
The vectors don't necessarily encode the context directly, but the higher-order conceptual space that each context exists in. For example, when the word "apple" is found in a sentence, its usage context could map to concepts like computers, corporations and fruit in a way that a particuler embedding might conceptually encode a context like "a computer corporation that uses the apple fruit as its logo" for that single word.
The magic in transformers layers on top as something of a derivative of this conceptual space, it's a higher-order space that allows encoding for concepts around the context of the word in relation to what you might consider "time" from the perspective of the words in a sentence. Maybe the word "apple" gets encoded to a vector that means something like "the first part in a metaphor using the comparison with a disimilar object to ultimately convey the futility of comparing two very disimilar things, with a fruit specifically not used as the comparable for added hyperbole".
I think that what we might call an LLM's "intelligence" is an emergent property of operating in the space of this complex encoding of rich conceptual worlds that allows the model to "learn" the use of words in the source material from many levels and perspectives simultaneously.
This is the space in which it was discovered language translation could be solved as a 2 step mapping through such a model: from language A to concept-space, then from concept-space to language B.
Paradox
A seeming paradox then lies in the fact that the model can show a strong ability to converge on a large number of high-level conceptual models, while at the same time being able to show zero ability to converge on conceptual models derived purely from that same higher order set, but in ways that did not appear in the training set. The uneasiness that I called "unanchored" is often described by users in terms of common sense: "it's really smart, but it seems to be lacking common sense".
I think instead that this particular uneasiness is rooted in interacting with something that seems to have intelligence, but lacks any capability to use deductive reasoning; this is a really foreign concept to us as capability in deductive reasoning seems to scale with intelligence everywhere in the natural world. This supposition seems supported by the fact that deductive logic tests, like "door with 'push' in mirrored writing" are a favorite when new models drop, precisely because people find it fascinating how poorly LLMs do with simple variations on puzzles well-represented in the training set.
So in a way, hallucinations or creativity are derived from noise in the model of conceptual encodings; most likely in concepts where there is little or no correlation of particular concepts represented in the training set; where even almost imperceptible input on the training side, or even just plain coincidence, can drive resolution of a particular signal from this noise; distracting from the fact that it can't actually reason. Since the hallucination is a probability-based choice across the concept space means that it will fit the usage in so many ways we expect, that it becomes extremely difficult to detect the lies in their subtlety, their multidimensional perfection.
Formalism
If I was a mathemetician, this is probably where I would create a new penrose-style diagram that shows multidimensional token-concept convergence in a really interesting and meaningful way.
It's important to note that this view of LLMs is purely my headcanon, my theory of mind on the topic. It's most likely wildly different from what's actually happening under the covers, but I'm translating this description from embeddings in my own mind's conceptual weightings (or lack therof as the case may be).
I'll even drop a conspiracy theory here: I think the only reason we've seen models leak is that those dropping "open" models have gotten good enough to do conceptual elision with pretty tight accuracy and nuance; frighteningly, most call this ability to just wipe a concept from existence "alignment".
Memories and Language
With theorising over the LLMs conceptual-level operation behind, we can start making hypotheses in the space beyond hunchwork on how we can best exploit and extend it.
In the Voyager paper, one point that the authors are particularly proud of is this code-based skills library that the LLMs have written for themselves, which generalizes between new worlds and can be persisted and easily audited by humans. The ineffectiveness of the Voyager model sans the ability to persist skills puts a particularly sharp point on its importance.
LLMs are notorious for forgetting things, and there are many strategies that those in the industry use to address this: growing context windows, important context memory persistence, and information databases like a vectordb over API docs. There is a constant tension between–and a lot of thought&tech around–keeping important things in context while not blowing the size limit.
In Voyager a few agents interact with eachother to iterate on deciding what to do, writing code (javascript targetting the mindflayer library), and mutating it as feedback on effictiveness inside the language interpreter and/or the game come in. This feedback loop together with persona instruction are intended to drive the agents to converge towards parameterized task-level generalization (matching the function-based skills library well).
Freedom of Conceptual Association
I think one important aspect of the Voyager architecture is that the LLM-based agents themselves get full control over coordinating the mapping between human language and code language, or between the concept and action spaces, if you will. By coordinating through human language, consuming human language infobases, and getting feedback in human language, they decide the functions to make, to refactor, and then decide when and which of them to call based on the task at hand.
The conceptual mapping between human language and the code of the library is accomplished by storing embeddings(concept space) of human language descriptions of each function into a vector DB. Importantly, however, the concepts distilled from the descriptions were themselves communicated by an agent asked to write a human language description given only the function's code.
The code's description and the conceptual representation stored in the vector DB holds as a tight simile to our own process of learning about a library's functions via documentation; it is the rare developer who can recall documentation for a library verbatim, but what is common is the ability to recollect its conceptual model; even in cases where conceptual recollection itself is too weak to make direct use of, it is strong enough to effect a single-shot search of a human language infobase.
The first place I remember seeing something in this vein was an interesting article awhile back about some research they were doing at "the artificial intelligence nonprofit lab founded by Elon Musk and Y Combinator president Sam Altman". They had a number of AI agents given, sometimes conflicting, goals together with a channel over which to communicate; the language used over the channel was left up to the AIs.
This stuck with me as an example of how interesting adaptive capabilities can emerge in AI in multi-agent systems, in particular when they get to set the rules of conceptual mapping. The fact that the Voyager skills library is ultimately stored in a language which humans can grok is at least as interesting as seeing what Musk and Altman's AIs had to say to eachother.
Play with my Cluster
If there's one thing we've learned in ML, it's that strategies that look like experimentation, evolution, and play are extremely powerful and this case is no different. Even though Voyager does not use gradient-based training or fine-tuning we can see that the persistent, goal-driven, feedback-style learning loop in Voyager, paired with thoughtful context control and infobase references, mimics the effects of reinforcement learning in an important way.
In Voyager the agents have what we could consider a higher-order persistent memory of solutions that it has derived in the action space indexed by conceptual needs it has encountered in the concept space. This is similar to how a neural net's weights are used to configure input to output correlations during the training process, with reference to a reward function, and is retained as its "memory" for use during inference.
So while you would definitely not want to release an unskilled agent on your production cluster, human or not, you probably wouldn't be so against it skilling up against a test environment with a high-quality curricula and a ruberic heavily weighted towards execution.
In the end, after a lot of trial and error, a lot of play, you may end up excitedly welcoming a highly-skilled (highly cloneable) agent to take intelligent control of your cluster.
Future of SysOps
In the world of operations, devops, SRE, whateveryoucallit, the job is exactly to create dynamic systems which can, at some level, operate themselves given conceptual-level expectations from an upstream human.
We spend a lot of time drawing from, and compromising between, a number of large and general conceptual domains to ultimately craft our own, more focused, Frankenstein's concept model of something like a PaaS. The goal for this constrained, collated, and aggregated model is to enable our users to more simply and expressively communicate their intent across the complex myriad higher level domains while only needing to speak in terms of our ostensibly simpler conceptual model.
For a long time, in the industry, we stagnated on a set of stale tools which fail pretty badly at being dynamic, autonomous, and bridging the gap to unknowledgable users. While these tools gave those who understand the internals of distributed infra more productivity through concept modeling, most systems lacked much automation outside that triggered by human action, relied too much on unreliable and undeterministic state mutation, and did little to pierce the 4th wall into devland.
We were given a breath of fresh air with the community and piles of code–paired with support by most hosting providers–in kubernetes; it dominates share of mind and workload and brought with it a few attributes important to building both the conceptual and feedback-driven executive aspects of our ideal infra models.
While having this interface–the operator model in particular is brilliant–does give us much more capability to define models of what infrastructure means to us, it's still a lot like using assembly language to write a GUI app. While experts benefit greatly from the addition of information-driven autonomy, and deep platform abstractions, we persist in a world where the conceptual domains exposed by the platform are still too complex to directly interact with, sometimes even for those with the commensurate knowledge.
The Beginning of the Future
I have a number of ideas, and have even done some experimentation already, but before I share any of it, and to reify in my own mind what I'm looking at, I needed to land this brain dump.
I think that one of the most powerful aspects of LLMs is their ability to shift between conceptual representations, and with conceptual computing already becoming popular, this pairing could be a harbinger of a major shift in HCI. Many areas of the industry are experimenting with HCI-through-LLM right now, but I think devops in particular is primed for the integration by virtue of it's concept-focused interfaces.
Please stay tuned for experiments around how we can we can teach LLMs to do k8s sysoping for great good.