
I wrote a large diatribe attempting to extol the virtues of kubernetes in an internal document, trying to sell it off as the perfect abstraction layer. The Linux kernel itself is the OS's arbiter between the hardware and software worlds and in fact plays an integral part of the container runtime. I view the job of k8s similar to the kernel's, but targeting some hypothetical world computer.
Not necessarily a world-size number of computers, but a unit of compute scheduling above that of a physical system. As we've (the computing public) moved our isolation capabilities to finer grains, from the machine, to the vm(many/machine), to the process(2-3x*many/machine), there has also been significant movement on the opposite side of the spectrum.
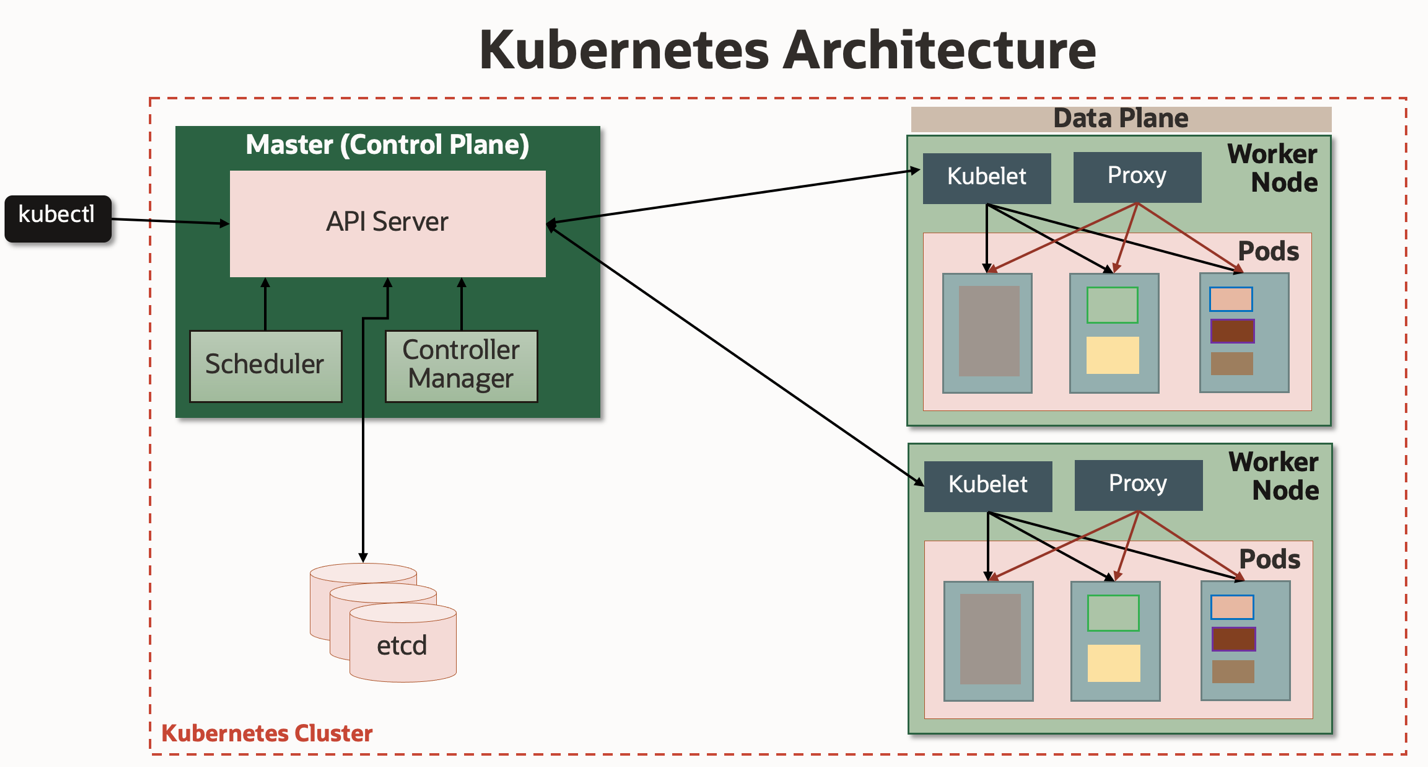
Like the Linux kernel presents comput task, network interface, and block storage abstractions over physical hardware, kubernetes provides compute task, CNI and CSI abstractions that are aware of the distributed system and expose the capabilities of the cluster to applications via a stable interface.
While our requirements may steer certain workloads into certain physical locations, the software itself should be able to be mostly agnostic to where it runs (think 12-factor). Things like multi-arch container images make this even more of a reality, as we see a coming proliferation in available target architectures and the already huge success in the armv7+arm64+x86_64 initiatives.
I have witnessed a small but vocal group pushing a "kubernetes is complex" view on the world. While it is true that kubernetes can be complex, necessarily from its attempt at abstracting over complexities. When the complexities beneath the abstraction have problems, you definitely want someone that understands the distributed systems.
But with a goal to make that abstraction more and more robust, there is a foreseeable future where the complexities no longer protrude; where the kubernetes kernel is as interface stable as the Linux kernel, and the need to delve beyond the veil is seen to be as complex a thing as debugging a kernel driver, isolated to the world of those who relish in such things.
The alternative, as I have seen, is either another abstraction a la openstack (expensive), or a small part of a disparate and lacking (and usually expensive) amalgamation of what's in kubernetes proper (in something like Hashicorp).
I don't want to love kubernetes-I'm often something of a contrarian-but in my personal experience using k8s and containerization, I feel it is as bigger a shift in our industry than VMs. But as I opined in my previous post, the k8s interface is far from the end of our journey; while I feel like investing in a greenfield project to compete with k8s is a bad bet, the place to invest resources is above the k8s abstractions.
There is so much inertia in the kubernetes project and those surrounding it that building on top of it in some way has been the only reasonable path to take, and is one that the cloud providers themselves have taken. There is so much value that is yet to be added on top that I'd consider some additions on top of a bare cluster to be requirements (we'll talk about these in the future) a la GNU to Linux's kernel.
So why is k8s Linux of the future?
It's stable under high dev velocity, performant, exposes stable resource abstractions, and the API and controller concept are brilliantly executed. All of this together gives us a highly extensible agent-driven execution environment with a unit of compute larger than a single host, one that should be capable of spanning the world. Above that is a target-rich environment for providing value in automation, processes, and UX that can potentially make it "easy to use".
This is the year of desktop kubernetes